YOLO (You Only Look Once)
* 해당 카테고리의 모든 글은 이후 작성자의 복습을 위한 포스팅입니다.

YOLO 논문링크: 링크
YOLO 사이트: https://pjreddie.com/darknet/yolo/
Introduction
사람은 이미지를 볼때 이미지 속 물체들이 무엇인지, 어디에 위치해 있는지를 한번에 알수 있다. 사람의 시각 시스템(Human visiual system)은 빠르고 정확하여, 적은 의식(conscious thought)으로도 운전과 같은 복잡한 일을 수행할 수 있다. R-CNN의 Region proposal method를 사용하여 첫 바운딩 박스를 생성하고 classification, post-processing에 이르는 복잡한 과정은 느리며 Optimize하기도 어렵다.
YOLO는 bounding box coordinate와 class probabilities를 single regression problem으로 간주하여, 이미지를 한 번 보는 것만으로 물체의 종류와 위치를 인식할 수 있다. 아래 그림과 같이 single convolutional network를 통해 다수개의 bouding box들을 생성하고 각 bouding box에 대한 class probabilities를 계산한다.

논문에서 설명하고 있는 YOLO의 장단점은 아래와 같다.
- 장점1. 간단한 처리과정으로 인하여 속도가 빠르다 (초당 45프레임 with Titan X GPU, fast version은 초당 150프레임). 또한, 다른 real-time system에 비하여 mAP가 2배 이상 높다.
- 장점2. sliding window나 region proposal-based techniques와는 달리 전체 이미지를 한번에 학습하기 때문에, 낮은 background error(False Positive, 검출되어야 하는데 그렇지 못함)를 가진다. Fast R-CNN에 비해 반도 안되는 background error를 가진다.
- 장점3. YOLO는 객체에 대한 일반화를 학습한다. 예를 들어, natural image로 학습하고 artwork로 테스트 했을 때, DPM이나 R-CNN과 같은 top detection method보다 더 높은 성능을 보여준다.
but,
- 단점1. 상대적으로 작은 개체들이 한곳에 모여있는 경우, 정확도가 낮다.
Unified Detection
System Overview

위 그림은 YOLO의 전체적인 시스템을 나타낸다. 아래는 설명.
- Input Image를 $S \times S$ grid로 나눈다.
- 모든 grid cell은 $B$개의 bounding box를 가지고 있고, 각각의 bounding box에 대한 confidence score를 가진다. $$ConfidenceScore = Pr(Object) \times IOU^{truth}_{pred}$$ 만약 cell안에 어떠한 물체도 없다면 confidence score는 0이 된다.
- 모든 bounding box는 5개의 prediction ($x, y, w, h, ConfidenceScore$)을 가진다. $(x, y)$는 grid cell의 경계를 기준으로한 bouding box의 중심좌표이다. $(w, h)$는 bouding box의 전체 이미지에 대한 width와 height의 비율이다.
- 각각의 grid cell은 $C$개의 conditional class probability를 갖는다. $$ConditionalClassProbability = Pr(Class_{i}|Object)$$
- 하나의 grid cell은 $B$의 크기와는 관계없이 한가지 Class에 대한 확률만 계산한다.
- Test time에는 Class-specific confidence score를 사용한다. $$ClassSpecificConfidenceScore = ConditionalClassProbability \times ConfidenceScore \\= Pr(Class_{i}|Object) \times Pr(Object) \times IOU^{truth}_{pred} \\= Pr(Class_{i}) \times IOU^{truth}_{pred}$$
논문에서는 Pascal VOC(20개 class, 링크)를 이용하여 YOLO의 성능을 평가했으며, $S, B, C$에는 각각 7, 2, 20이 할당되었다.
Network Design
YOLO는 GoogLeNet for image classification 모델(24 Convolutional layers + 2 Fully Connected layers)을 기반으로 한다. Fast-YOLO는 9개의 Conv만 사용한다.

이해를 돕기 위해 deepsystems.io의 슬라이드를 참고했다.

해당 모델의 마지막을 보면 $7 \times 7 \times 30$이라고 적혀있는데 이 중, $7 \times 7$은 49개의 grid cell을 나타낸다. 각각의 grid cell은 $B$개의 bouding box를 가지고 있는데 (해당 논문에서는 2), bouding box에는 5개의 값($x, y, w, h$)이 담겨져 있다. bouding box는 두개이므로 앞 10개의 원소는 이에 대한 값들이다.
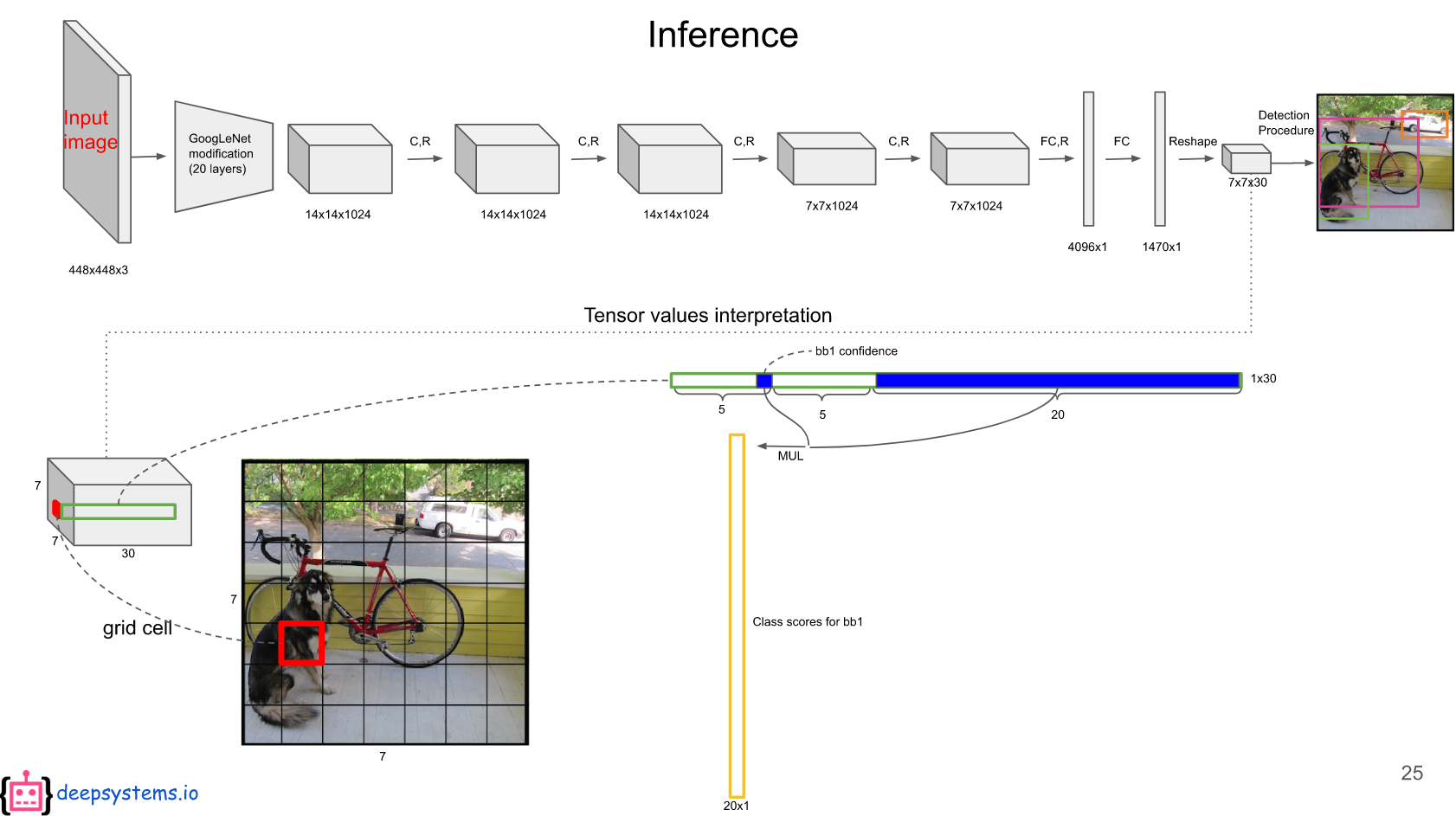
나머지 20개의 원소는 각 class에 대한 $ConditionalClassProbability$ 에 해당한다. 위 그림과 같이 bouding box의 $ConditionalScore$ 와 각 $ConditionalClassProbaility$ 를 곱하면 해당 bounding box의 $ClassSpecificConfidenceScore$ 가 나온다.

이와 같은 계산을 49개의 bouding box에 대해 계산하면 총 98개의 $ClassSpecificConfidenceScore$를 얻을 수 있다. 이 98개의 값들에 대해 20개의 클래스를 기준으로 NMS(non-maximum suppression, 해당 설명 참조)을 하여, 검출 결과를 결정한다.
Training
ImageNet 1000-class competitoin dataset을 이용해 20개의 Conv 레이어를 사전 훈련시켰다. 이렇게 사전 훈련된 네트워크에 나머지 Conv 레이어와 FC 레이어를 추가해 Object detection을 진행한다. 그리고 기존의 224 $\times$ 224 의 인풋 이미지에서 448 $\times$ 448 로 증가시켜 수행한다. 마지막 레이어는 class probabilities와 bouding box의 좌표를 예측한다.
YOLO는 훈련 시 사용되는 loss function을 이해하기 전에 몇가지 전제조건을 알아야한다.
- grid cell의 bouding box들 중, ground-truth box와의 IOU가 가장 높은 bouding box를 predictor로 설정한다.
- ground-truth box의 중심점이 어떤 grid cell의 내부에 위치하면, 그 grid cell에는 Object가 존재한다고 생각한다.
- 위의 기준에 따라 아래와 같은 notation들이 사용된다.

(1) Object가 존재하는 grid cell $i$의 bouding box $j$
(2) Object가 존재하지 않는 grid cell $i$의 bouding box $j$
(3) Object가 존재하는 grid cell $i$
Loss Function:

첫줄부터 차례대로 (1), (2), (3), (4), (5)라고 하겠다.
(1) Object가 존재하는 grid cell $i$의 bounding box $j$에 대해 $(x, y)$에 대한 loss를 계산. sum squared error를 이용.
(2) Object가 존재하는 grid cell $i$의 bounding box $j$에 대해 $(w, h)$에 대한 loss를 계산. $(x, y)$를 계산할 때와 달리 제곱근을 취한뒤 sum squared error를 진행한다. 이는 bouding box의 크기에 따른 불림함을 없애기 위함이다.
(3) Object가 존재하는 grid cell $i$의 bounding box $j$에 대해 $ConfidenceScore$에 대한 loss를 계산 ($C_{i} = 1$).
(4) Object가 존재하지 않는 grid cell $i$의 bounding box $j$에 대해 $ConfidenceScore$에 대한 loss를 계산 ($C_{i} = 0$).
(5) Object가 존재하는 grid cell $i$에 대해 $ConditionalClassProbability$의 loss를 계산 ($CorrectClass: p_{i}(x) = 1, $ $otherwise: p_{i}(c) = 0$).
$\lambda _{coord}$: $(x, y, w, h)$에 대한 loss와 다른 loss들과의 균형을 위한 parameter (논문에서는 =5).
$\lambda _{noobj}$: Object가 있는 box와 없는 box간의 균형을 위한 parameter (논문에서는 =0.5, 일반적으로 작은 수로 설정, 이유는 보통 obj가 있는 cell보다 없는 cell의 수가 더 크기 때문).
Training Details:
- Batch Size: 64
- Momentum: 0.9 and a decay of 0.0005
- Learning Rate: 0.001에서 0.01로 epoch마다 천천히 상승시킴 (처음부터 높은 lr은 발산의 가능성이 있음). 그 후, 0.01로 75 epochs, 0.001로 30 epochs, 그리고 마지막으로 0.0001로 30 epochs 훈련.
- Dropout layer Rate: 0.5
- Data augmentation: random scaling and translations of up to 20% of the original image size.
- Activation function: leaky rectified linear activation

Limitations of YOLO
- 하나의 grid cell은 하나의 class만을 예측하므로, 작은 Object들이 모여있는 이미지에 대해 낮은 정확도를 가짐.
- bounding box가 training data를 통해서만 학습되므로, 새로운 형태(예를 들어, 방패연과 가오리연의 인식, 또는 unusal aspect ratio 등)에 대한 인식이 취약함.
- 몇 단계의 layer를 거쳐서 나온 결과로 bouding box를 예측하므로 localization에 대한 오류가 발생.
Experiments

다른 Real-Time Detectors에 비해 높은 mAP 및 빠른 FPS를 보여준다.

Fast R-CNN에 비해 낮은 Background error를 보여준다.


YOLO와 Fast R-CNN을 결합하면 기존의 Background error를 낮추며 mAP를 증가시킬 수 있다(71.5% -> 75.0%). 위쪽 그림에서 다른 결과들은 top Fast R-CNN 모델과 다른 버전의 Fast R-CNN 모델을 합친 결과.

Natural image로 학습하고 Artwork detection을 진행할 때도 좋은 성능을 보여준다.
Conclusion

YOLO는 classifier-based 방법과는 달리 loss function에 직접적으로 detection 성능에 직접적으로 대응하는 요소들을 넣어 학습시킨다. YOLO의 가장 큰 장점은 간다하며 빠르다는 점이다.
참고 자료: